In this chapter we look at a little bit of the history of the web and how HTML has evolved into HTML5 over the years. We introduce the concepts of clients and a server and how requests for HTML are served between the two. Finally we give a brief overview of working with documents and then create our first web page.
1.1 - Internet History and Usage
The World Wide Web (WWW) is pervasive in daily life. Since surfing the Web and using email are routine activities for most people, it seems as though these technologies have been around forever. Certainly, the underlying technology of the Internet goes back at least 40 years, but the Web is a recent phenomenon that has experienced major growth within the past decade.
Like most technologies, the Web evolved from technological predecessors that were unable to predict the final form into which they would morph. Technology has a way of starting with a nascent sense of purpose that forever branches into arenas that were not imagined at the start. Historical development of these background technologies provides an interesting canvas upon which to paint what is still an adolescent portrait of the Web.
ARPANET - Internet Beginnings - TOP

Figure 1-1.
Sputnik
The Advanced Research Projects Agency (ARPA) was created in 1957 in response to the Soviet Union's successful launch of Sputnik ‒ the world's first artificial satellite. Funded by the Department of Defense, the Agency brought together the human intelligence needed for America's first successful satellite launch 18 months later. By 1962, however, ARPA's purpose had expanded to encompass the application of computers to military technology, and a significant part of the expansion dealt with computer communications and networking.
A persistent problem in research and development is bringing together the needed intellectual capital to work on problems or exploit opportunities. Since experts are often times scattered geographically, it makes it difficult to maintain interaction among participants or hinders the continuity of projects. Therefore, electronic communications were deemed an important area of investigation to support ARPA work efforts.
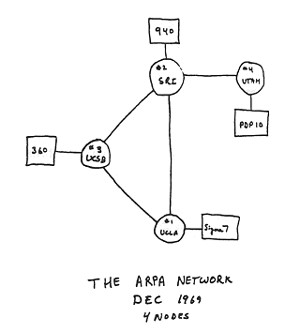
Figure 1-2
ARPANET original drawing
In addition, the Cold War raised concerns about the impact that nuclear war could have on the integrity of computer networks to sustain military command and control. It was unacceptable to think that even a minor network outage could disrupt military command, thereby tampering with the final outcome of a major war and increasing the spread of devastation. Thus, the need to support research cooperation among scientists and engineers combined with concerns about network vulnerability led to the concept of distributed packet switching as the preferred computer communications model.
In this model, network transmissions are split into small packets that may take different routes to their destination through different nodes ‒ through different computers ‒ along the network. Computers hand off packets of data from one to another through various routes, and the destination computer collects all the packets and reassembles them into the original message. By transmitting different pieces of a message along different routes, the security of the message is heightened. Also, since a packet can travel various routes to its destination, an alternate route can be used if the first route is malfunctioning. As a result, a distributed network of interconnecting computers is more secure and can better withstand large scale destruction than can a centralized network connected to one or a few host computers.
In 1969, the Department of Defense commissioned ARPANET for research into networking. The first node was at UCLA, closely followed by nodes at Stanford Research Institute, the University of California at Santa Barbara, and the University of Utah. By 1972, much of the work of developing hardware, software, and communications protocols had shifted to universities and research labs. By 1973, ARPANET had linked 40 machines and had international connections to England and Norway.

Figure 1-3.
Dr. Leonard Kleinrock
Dr. Leonard Kleinrock is known as the inventor of Internet technology, having created the basic principles of packet switching while a graduate student at MIT. This was a decade before the birth of the Internet which occurred when his host computer at UCLA became the first node of the Internet in September 1969. He wrote the first paper and published the first book on the subject; he also directed the transmission of the first message ever to pass over the Internet.
One of the issues in computer communications is the reliability of messages sent from one computer to another. It is possible, if not probable, that the computers are different makes and models and have different methods for sending and receiving packets of electronic information. When the information does not reach the intended computer because of transmission problems, the issue of lost packets comes into focus. These concerns led to the development of TCP (Transmission Control Protocol) to ensure reliable connections between diverse governmental, military, and educational networks. The parallel development of IP (Internet Protocol) dealt with the problems of assembling packets of data and ensuring those packets reached the correct destinations.
By 1982 it had been decided that ARPANET was to be built around the TCP/IP protocol suite. Doing so enabled direct communications between computers using land lines, radio, and satellite links among different networks of computers. At this point, an "internet" became defined as a connected set of networks, specifically those networks interconnected through TCP/IP. That same year External Gateway Protocol (EGP) specifications were drawn up under which different networks communicated with one another. By 1984, over 1,000 host computers were part of ARPANET. Domain Name Servers (DNS) were introduced to permit use of host names (e.g., "www.cox.net"), and numeric IP addresses (68.1.17.9) were introduced for identifying and linking computers on the networks.
NSFNET - Internet Growth - TOP
Expansion of what now had become the Internet began in 1986 through funding by the National Science Foundation. The NSFNET was originally designed to link supercomputers at major research institutions, but it quickly grew to encompass most major universities and research and development labs. By 1990, there were over 300,000 host computers. In 1994, a report commissioned by the NSF entitled "Realizing The Information Future: The Internet and Beyond" was released. This report presented a blueprint for the evolution of the "information superhighway" and had a major impact on the way the Internet was to evolve.
In 1995, after a short but successful history, NSFNET was "defunded" and restrictions were lifted on commercial use. At this point, the stage had been set for exponential growth in Internet usage. Funding that previously supported NSFNET was redistributed to regional networks to help purchase Internet connectivity from the now numerous, commercial network service providers. Over the next three years, host sites increased by a million per year. During 1995-1997, the number of sites increased by over 6 million per year to nearly 20 million host sites. By now, government agencies, educational institutions, and private enterprises were all energetic clients of the Internet.
On October 24, 1995, the Federal Networking Council unanimously passed a resolution defining the term Internet:
"Internet" refers to the global information system that -- (i) is logically linked together by a globally unique address space based on the Internet Protocol (IP) or its subsequent extensions/follow-ons; (ii) is able to support communications using the Transmission Control Protocol/Internet Protocol (TCP/IP) suite or its subsequent extensions/follow-ons, and/or other IP-compatible protocols; and (iii) provides, uses or makes accessible, either publicly or privately, high level services layered on the communications and related infrastructure described herein.
The Internet can be thought of as a technical infrastructure composed of computers, cables, networks, and switching mechanisms by which one computer can communicate with another computer. In the final analysis, the benefits of networked computers are realized by the information being exchanged among the people sitting behind the computers. From the start, email and file transfer programs were integral to the purpose behind the Internet. Such programs allowed people to keep in touch with each other and gather all the information they needed.
WWW - Information Net - TOP
Although email and file transfer methods were important to Internet growth, they did not provide the "user friendly" methods needed by novice users to get to the growing repositories of information scattered around the world. It was still very much a technical issue to communicate through the Internet. Realization of the goal of an information superhighway required the development of tools to "hide" Internet technology behind a human interface. This came with the development of the World Wide Web and Internet browser software.

Figure 1.4
Ted Nelson
In the mid-1960s Ted Nelson coined the word "hypertext" to describe a system of non-sequential links between text. The idea was to navigate among textual references without having to read material in a linear sequence. A piece of information here would lead to a related piece of information there in a chain of links to gather intelligence from sources scattered throughout multiple documents. It was not until fifteen years later that Tim Berners-Lee, a consulted with the European Laboratory for Particle Physics (CERN), wrote a program entitled "Enquire-Within-Upon-Everything" which allowed links to be made between arbitrary text nodes in a document. Each node had a title identifier and a list of bidirectional links so readers could jump from one section of a document to another by activating the text links.

Figure 1.5
Tim Berners-Lee
In 1990 Berners-Lee started work on a hypertext "browser". He coined the term "WorldWideWeb" as a name for the program and "World Wide Web" as a name for the project. The WWW project was originally developed to provide a distributed hypermedia system from which any desktop computer could easily access physics research spread across the world. The Web included standard formats for text, graphics, sound, and video which could be indexed easily and searched by all networked machines. Standards were proposed for a Uniform Resource Locator (URL): the addressing scheme for the Web; the HyperText Transfer Protocol (HTTP): the set of network rules for transmitting Web pages; and the HyperText Markup Language (HTML): the subject of this tutorial.
The prototype browser was written for the not widely used Apple Next computer. A simplified version adaptable to any computer platform was built as the "Line-Mode Browser," and was released by CERN as freeware. Berners-Lee later moved to Massachusetts Institute of Technology (MIT) and helped found the World Wide Web Consortium (W3C) which today maintains standards for Web technologies.
In January 1993, Marc Andreessen, who was working for the National Center for Supercomputing Applications at the University of Illinois, released a version of his new point-and-click graphical browser for the Web that was designed to run on Unix machines. In August, Andreessen and his co-workers at NCSA released free versions for Macintosh and Windows. Andreessen and Eric Bina developed the Mosaic browser and later founded Netscape Corporation to produce the Navigator browser: the offspring of the Mosaic browser and one of the first and most popular commercial browsers. In August 1994, NCSA assigned all commercial rights to Mosaic to Spyglass, Inc. Spyglass subsequently licensed its technology to several other companies, including Microsoft for use in Internet Explorer. It was not until 1996 that Microsoft became a major player in the browser market. Today, however, Google Chrome has become the most popular browser with approximately 51% of worldwide market share.
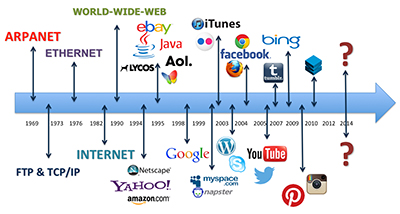
Figure 1.6
The diagram, developed by the Malone Media Group, outlines the History of the Internet.
As the Internet evolved and became available to the general public in the 1990s, ISP companies such as AOL, CompuServe, and Prodigy allowed people to gain access to the World Wide Web directly from their home computers. This led to the growth of Electronic Commerce (e-commerce). In 1995, Amazon.com set the standard for a customer-oriented e-commerce Web site.
The era of social media took off in the early 2000's with the release of Friendster. This was followed by LinkedIn and MySpace in 2003, and the launch of Facebook in 2004. Since then other social media applications like Instagram, Twitter, and Pinterest have gained popularity in both mobile and desktop environments.
Today, over three billion people have access to the Internet. The World Wide Web provides access to social media, shopping, business transactions, research and learning. There is no doubt that the World Wide Web will continue to evolve and provide even greater access to resources.
Technical Convergence - TOP
The Internet has been a convergence of many technologies brought together for the purpose of sharing information electronically. Today, the Internet is a system of interconnected networks that uses common communications protocols, or rules of exchange, to transmit information among computers. One of these protocols is the HyperText Transfer Protocol (HTTP). HTTP governs the exchange of hypertext documents, or Web pages, between computers. Information exchanges that use this protocol are collectively called the World Wide Web (WWW). Other Internet protocols include those used for transferring files ‒ the File Transfer Protocol (FTP) ‒ and for exchanging email ‒ the Simple Mail Transfer Protocol (SMTP). The Internet, then, is not a single entity. It integrates many different ways of maintaining and exchanging information among many different computers on many different networks scattered around the world.
The World Wide Web is one such collection of information exchange methods. It is based on the use of Web pages as the mechanisms for packaging and transmitting information among computers connected to the Internet. A Web page includes textual information along with links to related textual or graphical content located anywhere else on the Internet. The information is formatted for presentation using the HyperText Markup Language (HTML) to arrange and style presented information and to link to other content on distant computers. This formatting language is the key to unlocking and bringing world-wide repositories of information to the computer desktop. It is also the means by which personal information is shared with the world. HTML, being the subject of these tutorials, will be examined in depth.
From these beginnings, the World Wide Web has grown into the primary infrastructure to deliver information around the globe. A single individual can establish a Web presence accessible by anyone else in world with an Internet connection; and a single company can establish a Web site to take part in the global marketplace of products and services. Although the Web began as a public utility with limited scope, today it has grown, through the entrepreneurship of individuals and organizations, into what its name implies — a worldwide web of interconnected networks to conduct the public and private affairs of the world community.
In 1969, the Internet began with four nodes and four users. In 2015, according to Internet Live Stats, there are over 3 billion Internet users worldwide which equates to approximately 40% of the world population. Unfortunately, internet expansion has not been equal around the globe. Countries with the intellectual and managerial talent along with the political and economic systems to promote that talent typically lead the way.
When countries are classified by region, Internet usage rankings appear as shown in Table 1-2. The Americas and European countries account for less than 50% worldwide usage the largest number of users are found in Asian countries.
| Rank | Region | Users | Percent |
|---|---|---|---|
| 1 | Asia | 1,322,491,069 | 48.4% |
| 2 | Americas (North and South) | 596,331,291 | 21.8% |
| 3 | Europe | 520,381,481 | 19% |
| 4 | Africa | 268,209,162 | 9.8% |
| 5 | Oceania | 25,109,590 | 0.9% |
Internet Technologies - TOP
For most of the decades leading to the present, Internet connection was slow. Users were restricted to using existing telephone lines with unreliable dial-up connections. Until recently, most users connected to the Internet at speeds topping out at 56,000 bits of information per second. The last few years, however, have witnessed a significant rise in Internet speeds through the availability of Digital Subscriber Lines (DSL) and cable modem connections with speeds of up to 5,000,000 bits per second. These broadband connections to the Internet continue to rise in the U.S. Today, approximately 70% of Americans have some type of broadband access to the Internet.
Most workers in the U.S. also have high-speed lines to the Internet through their company's network connections. As of mid-2005, over 80% of workers had access to high-speed connections.
In developing Web pages, it is important to know the target browsers being used by site visitors. Browsers differ in their underlying technologies and the extent to which they support common standards. There are few guarantees that a Web page will display the same way through two different browsers. Statistics reported in Table 1-2 show the percentages of browsers in use today.
| Browser | Percent |
|---|---|
| Chrome | 46.2% |
| Internet Explorer | 13.5% |
| Safari | 16.4% |
| Firefox | 13.2% |
| Opera | 3.9% |
If you are designing Web pages for a known audience with a known browser then your development efforts become relatively easy. It is necessary only to test your pages through that particular browser. In designing for the general public, you need to make assumptions about your likely audience. Ideally, you should test your pages on all of the most popular browsers. For example, test pages on both Internet Explorer and Firefox. As a general rule, if you follow the W3C standards presented in these tutorials, your pages will have the best chance of being displayed correctly on all browsers that follow the outlined standards.
All modern PC monitors can display in 1366 x 768 (pixels) screen resolution or higher, and many users choose this resolution for displaying Web pages. A safe approach is to design Web pages for display at 1366 x 768 resolution unless you are aware that your audience prefers the larger page sizes possible under higher resolutions. With technology quickly advancing, in a very few years 1366 x 768 resolution will become the minimum standard.
It should be noted that screen resolution is not related to screen size. Even small screens (15" or 17" for example) can be set to high resolution display depending on the amount of video memory installed in the system. Still, the window size within which the browser is opened can have a significant effect on Web page display. A full-screen display of a page normally looks different from a page opened in a smaller window because the page adjusts its layout to the window size. This automatic adjustment permits the page to expand or contract to the chosen window width, and makes it less crucial to design for a particular screen resolution or a particular window size.
When displaying color graphics on a page, consideration needs to be given to the color depth (the range of colors) of monitors. There are three common color precision modes. Users with older PC normally have 8-bit (256 colors) monitors (only about 1% of users have this restriction). Other users vary between 16-bit (65,536 colors) and 24-bit (16,777,216 colors) monitors which represents approximately 18% and 72% of users, respectively. When creating your own graphics, you have the choice of the color depth displayed. When using prepared graphics, you may not have this choice. Just be aware that images saved with high color depths may not accurately display colors on monitors with small amounts of video memory and fewer possible colors.
Given the trends in Web technologies, the good news for Web developers is that fairly modern computer systems are in preponderance. This means that it is usually safe to use the latest Web technologies in authoring Web pages with little need to compromise best practices to reach audiences with older technologies. The best bet is to design for the Internet Explorer browser displayed at 11366 x 768 resolution at a color depth of 32-bits in a full-screen window. Adjustments can be made for other browsers, other screen resolutions, and other color precisions if it is reasonable to expect page visits by users with other technologies.
Internet Standards and Coordination - TOP
The Internet is a global network that is not run or managed by a single person or group. Each separate network that makes up the Internet is managed individually. There are however, a number of groups that develop standards and guidelines.
The Internet Society (ISOC) is an independent international nonprofit organization founded in 1992 to provide leadership in Internet related standards, education, and policy around the world. The Internet Society is home to the Internet Engineering Task Force (IETF) and the Internet Architecture Board (IAB) which are responsible for Internet infrastructure standards.

The Internet Engineering Task Force (IETF) is a large open international community of network designers, operators, vendors, and researchers concerned with the evolution of the Internet architecture and the smooth operation of the Internet. It is open to any interested individual.

The Internet Architecture Board (IAB) is a committee of the IETF that provides guidance and direction to the IETF. A major function of the IAB is the publication of the Request for Comments (RFC) document series. A Request for Comments (RFC) is a memorandum published by the Internet Engineering Task Force (IETF) describing methods, behaviors, research, or innovations applicable to the working of the Internet and Internet-connected systems.Through the Internet Society, engineers and computer scientists may publish discourse in the form of an RFC, either for peer review or simply to convey new concepts, information, or (occasionally) engineering humor. The IETF adopts some of the proposals published as RFCs as Internet standards.
1.2 - Serving Web Pages
Serving Web Pages
The World Wide Web, as the name implies, is a world-wide network of computers that share documents called Web pages through an expansive "web" of network connections. The Web, being a part of the Internet, allows page sharing to take place between computers located anywhere in the world.
Servers and Clients
There are two types of computers that connect to the Internet and make document sharing possible. Web server computers are the storehouses of Web pages. A Web page must be placed on a server computer that is linked to the Internet before the page can be accessed. Web client computers are the desktop PCs that link to these servers to access the Web documents stored there. These client PCs run Web browser software to download documents from the servers and display the retrieved pages.
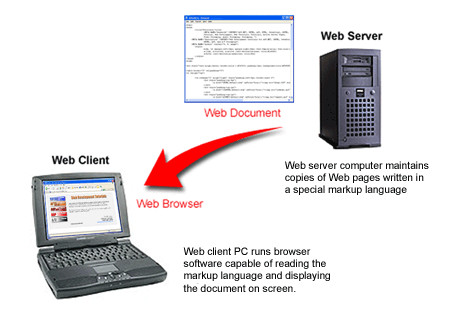
Figure 1-6.
Accessing a Web page from a server for display on a PC client.
Accessing Web Documents
Users interact with the World Wide Web through Web browser software. In order to retrieve a Web page located on a particular Web server, special addressing is used to identify the server and the page of interest. A Uniform Resource Identifier (URI) is used to identify a resource on the Internet. A Uniform Resource Locator (URL) is a special type of URI which represents the network location of a resource such as a Web page. This Uniform Resource Locator (URL) or web address is entered into the browser's address box and sent across the Internet in search of the server.
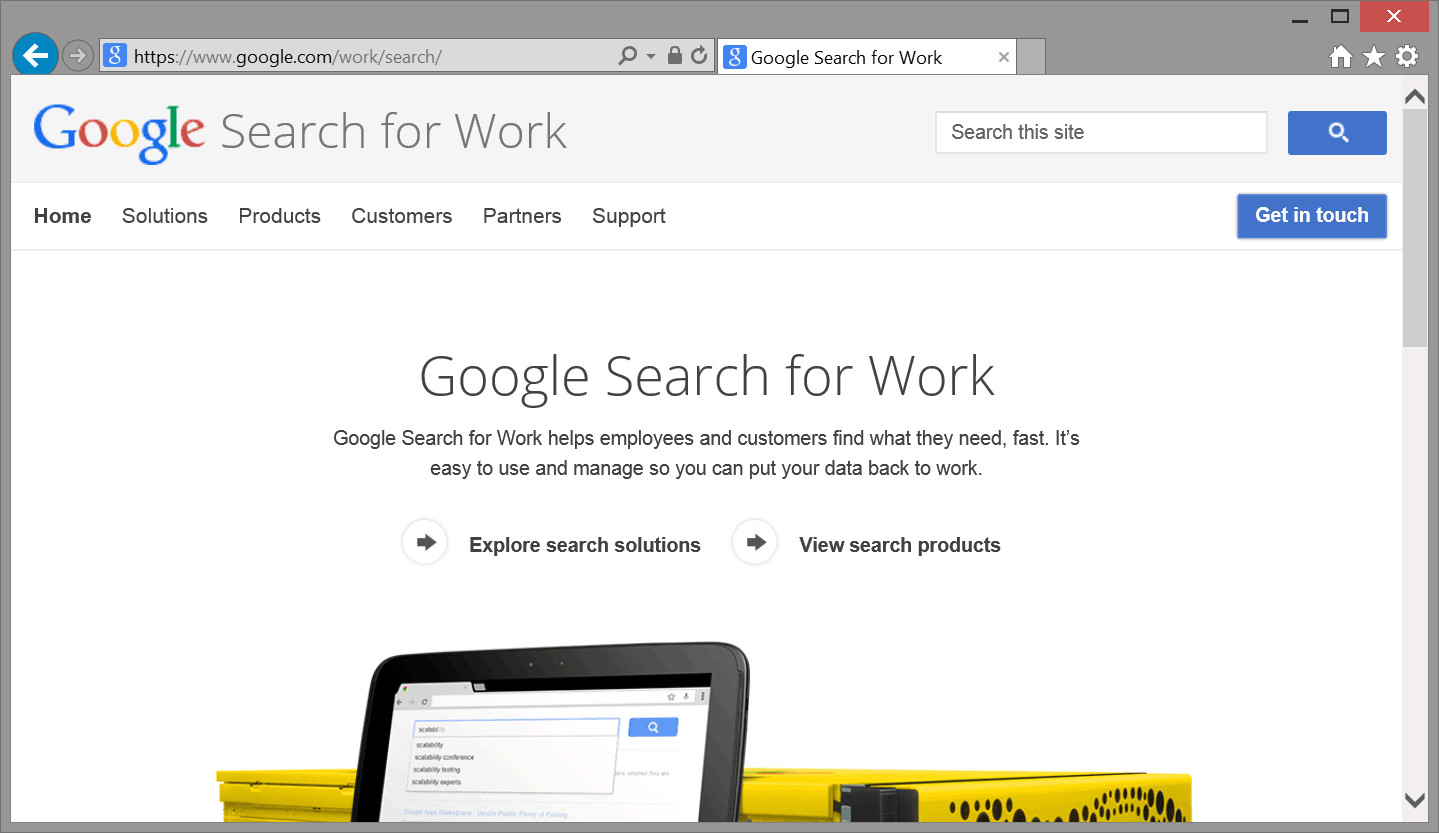
Figure 1-7.
The URL of the page shown in Figure 1-7 is https://www.google.com/work/search/
A URL is composed of several parts:
| protocol | The "http" portion of the address specifies the network transmission method (the protocol) used to search out and deliver the page to the browser. HTTP is the HyperText Transfer Protocol ‒ the standard method used to interact with the World Wide Web. |
|---|---|
| domain name | The www.google.com portion of the address specifies the name of the server. Virtually all Web servers are assigned domain names for unique identity among all servers on the Internet. In the absence of a name, servers can be located by their numeric Internet Protocol (IP) addresses in the dotted format 000.000.000.000. Normally, though, domain names are used since IP addresses are difficult to remember. |
| path | On arrival at the server, the directory path to the Web page is traversed to locate the particular document to retrieve. The Web page in Figure 1-7 is on the path work/search/; that is, the document is located in the mini directory, which is a subdirectory of the enterprise directory. |
| file name | The document file name is the final part of the path. The Web page in Figure 1-7 is named index.html, and is located in the search directory. |
Normally, you would need to know the exact name of the Web page in order to retrieve it; however, if the page is named index.html as in the above example, then that page is retrieved even if a page name is not provided in the URL. The name, index.html along with other special names such as index.html, or default.html, signifies a default page that is retrieved if no page name is provided. This is why you are able to retrieve a Web page from the Internet with a simple domain name URL (http://www.google.com, for example). In the main Web directory for the site is a page with one of these special names that is retrieved. This default page is often referred to as the home page for the site.
URI
Although the term "URL" is in common usage, it is more accurate to refer to a Web address as a URI (Uniform Resource Identifier). This term recognizes that Web resources are more than just Web pages; they can include graphic images, multimedia files, downloadable word processing, spreadsheet, and database files, electronic mailboxes, and a host of other document types and Web services. Once the Web document is located, it is retrieved by the server and sent back across the Internet to the requesting PC. The client PC is identified on the Internet in the same way as the server. It has a unique IP address that is transmitted to the server along with the URL request for the Web page. You may not know the IP address of your computer but it is assigned by your Internet Service Provider (ISP) when connecting to the Internet. This allows the Web server to deliver requested pages directly back to the requesting PC.
Top Level Domain Names
| .aero | Air-transport industry |
|---|---|
| .asia | Pan-Asia and Asia Pacific community |
| .biz | Business |
| .cat | Catalan linguistic and cultural community |
| .com | Commercial entities |
| .coop | Cooperative |
| .edu | Restricted to accredited degree-granting institutions of higher education |
| .gov | Restricted to government use |
| .info | Unrestricted use |
| .jobs | Human Resource management community |
| .mil | Restricted to Military use |
| .mobi | Corresponds to a .com Web site - the .mobi site is designed for easy access by mobile devices |
| .museum | Museums |
| .name | Individuals |
| .net | Entities associated with network support of the Internet, ISPs or telecommunication companies |
| .org | Nonprofit entities |
| .travel | Travel Industry |
Viewing Local Web Pages
In addition to being served across the Internet, Web pages can be accessed locally. Personal Web pages can be saved on your desktop PC and opened in your browser. They can be treated just like any other file on your computer. In fact, all Web documents described in this tutorial can be created on, saved to, and retrieved for display from your desktop PC.

Figure 1-8.
Web Page Icon
In order to open a local Web document in your browser, you can double-click the document icon on your desktop. This action automatically opens your browser and displays the page.
You can also view a local Web page by first opening your browser, pressing Ctrl + O, and browsing your disk directories to locate the document, and opening the document. This process is illustrated in Figure 1-9.
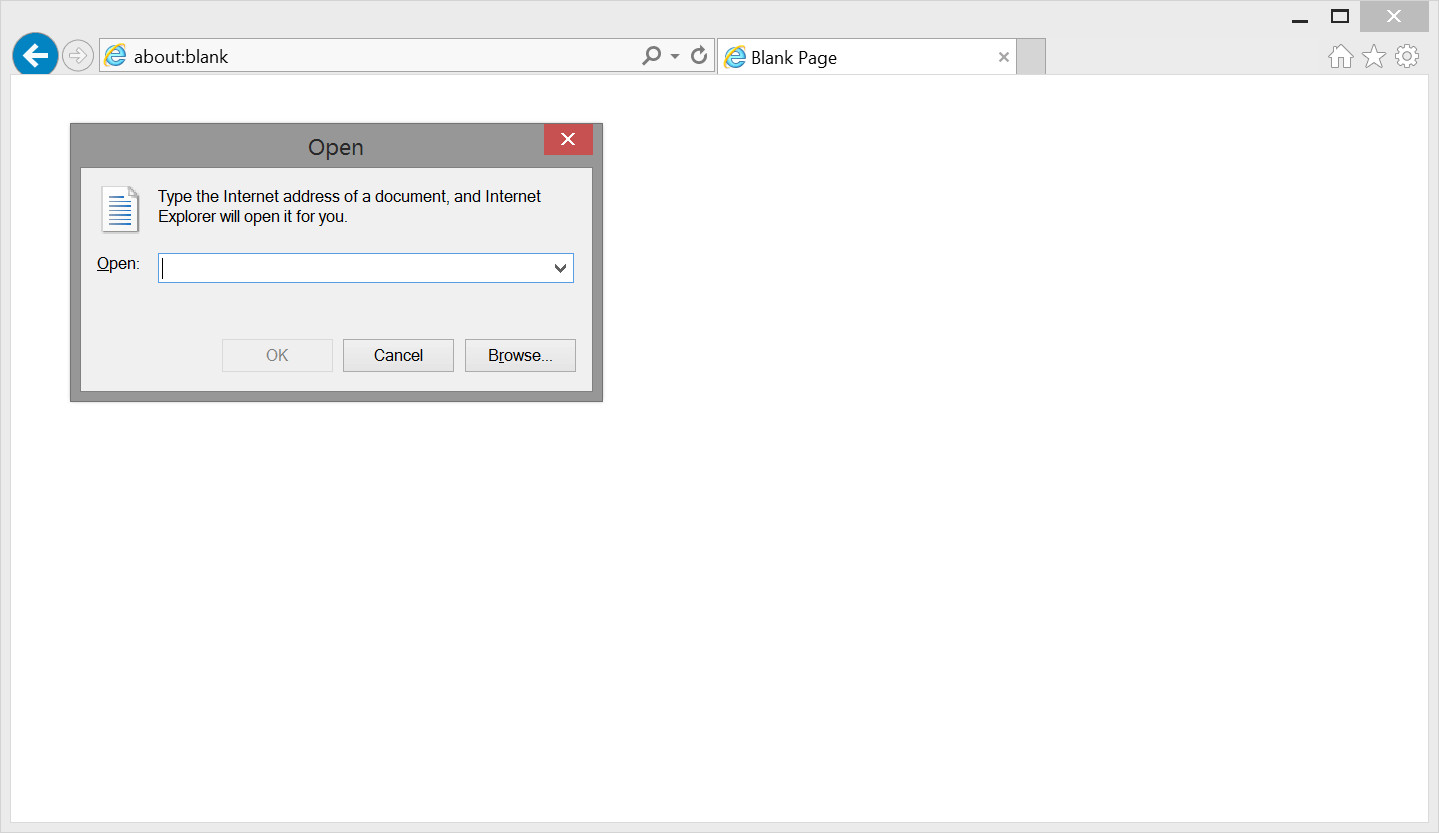
Figure 1-9.
Opening a local web page.
Creating a Web Presence
Although you do not need an Internet connection to create and display Web pages, if you wish to make your pages accessible by other PC clients ‒ such as your friends and neighbors around the world ‒ you will need to copy your pages to a Web server connected to the Internet. If you have Internet services at your home or business, it is likely that your ISP provides you with a home directory for storing personal Web pages. Usually, it is an easy process to connect to this directory and upload pages. By doing so, even the pages that you create with this tutorial become available to the world. Your ISP will supply you with the URL address necessary to access your pages across the Internet.
1.3 - HTML Tags and CSS Styles
HTML Tags and CSS Styles
A Web page originates as a standard text file containing the information to be displayed along with formatting instructions for its presentation on the computer screen. These formatting instructions are written in a special markup language, so-called because it is used to "mark up" the information on the page to describe its arrangement and appearance when rendered in a Web browser.
HTML Markup Language
From the beginning, the markup language for Web pages has been the HyperText Markup Language (HTML). It functions by surrounding text and graphic content appearing on the page with special codes instructing the browser on how to arrange and display the content. As a very simple example the line of code shown in Listing 1-1.
HTML is based on the Standard Generalized Markup Language (SGML), a standard for specifying a markup language or tag set. SGML is not a document language, but a description of how to specify one and create a document type definition (DTD). When Tim Berners-Lee created HTML, he used SGML to create the specification.
<h2>Format this line of text</h2>Listing 1-1. HTML code to format a line of text.
The text string Format this line of text. It is surrounded with the HTML markup codes <h2> and </h2> (heading 2 style) in order to display the text in the style shown in Figure 1-2.
Format this line of text.
Figure 1-2. Browser output of formatted line of text.
These markup codes instruct the browser to format the text by applying sizing and bolding to the characters appearing between them. Markup codes, also called HTML tags or elements, are always enclosed inside "<" and ">" symbols to set them apart from the text content to which they apply. Normally, an "opening" tag indicates the beginning point of formatting (<h2> in the above example), and a separate "closing" tag indicates the ending point of formatting (</h2> in the above example). By learning the available HTML tags, you can create your own Web pages to present your text and graphics in almost any way you choose.
Learning HTML
HTML is not a computer programming language. It is simply a set of markup codes that structure and style text and graphics appearing on a Web page. Learning HTML is, basically, learning these markup tags and how to use them to style your Web pages.
There certainly are methods available to create Web pages without having to learn HTML. You already may be familiar with Microsoft Visual Studio or Adobe Dreamweaver. These are drag-and-drop, WYSIWYG ("what-you-see-is-what-you-get") Web page editors that produce the underlying HTML codes for you. In fact, you can, make Web pages with these software packages in total ignorance of HTML. Why, then, bother to learn HTML?
If you are a casual or occasional Web page author who maintains a simple, personal Web site, then it is probably sufficient to remain in the dark about HTML. A visual, drag-and-drop editor permits you to compose and arrange page content without knowledge of the underlying code. Ignorance is bliss. As a knowledgeable developer, though, one with professional responsibility for creating and maintaining commercial sites, it is vitally important to know the HTML language. This is the case even if you use visual editors to create pages. As Web applications become more sophisticated, you need to be able to take pages apart and put them back together again at the code level rather than just at the content level. In a sense, you need to be able to raise the hood and tinker with the engine.
It is a common occurrence that once students have been exposed to HTML coding they actually come to prefer working at the code level rather than using WYSIWYG authoring tools. They have more control over page designs and, quite often, they will find it easier to work directly with the code than through the editor software. Hopefully, this will be your experience as you learn the HTML language.
Evolving HTML Standards
As noted, the World Wide Web Consortium (W3C) maintains standards for Internet technologies, including standards for Web markup languages. The earliest standard for HTML appeared in 1995, and was followed by versions HTML 3.0, HTML 3.2, and culminating in HTML 4.01 in 1999. Subsequent to this latest HTML standard, an extensive reformulation of markup languages occurred.
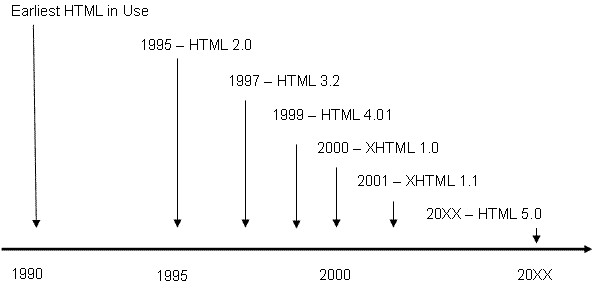
Figure 1-11.
Evolving HTML Versions
By 2001 W3C efforts had focused on defining a new XML (eXtensible Markup Language) language for use as a universal markup language by replacing older languages with standards for creating future languages for special markup needs. For instance, versions of XML had been designed for generating Web graphics (VML - Vector Markup Language), for displaying mathematical equations (MathML - Mathematical Markup Language), for authoring interactive audio/video presentations (SMIL - Synchronized Multimedia Integration Language), and for digital signature recognition (InkML - Ink Markup Language), and others.
Efforts to reformulate HTML 4 as an XML-based language led to the eXtensible HyperText Markup Language (XHTML). The initial version, XHTML 1.0, appeared in the year 2000 as a transitional standard that still recognized some of the popular features of HTML. By 2001, it had evolved into version XHTML 1.1 and had completely abandoned the hold-over features of previous HTML standards. HTML 5, accepted in October 2014 by the W3C, incorporates features of both HTML and XHTML, adds new elements, and is intended to be backwards compatible. A more detailed overview can be found at the W3C HTML 5 Web site.
Although some are more successfully than others, various browser products attempt to honor HTML and XHTML standards. For example, if you are using current versions of Internet Explorer or Firefox, you have all the capabilities needed for learning and applying the XHTML/HTML language described in these tutorials.
HTML 5
HTML 5 is the next generation of HTML and is replacing both HTML 4 and XHTML, and the HTML DOM. HTML5 was accepted by the W3C in October of 2014. This tutorial focuses on the core elements supported in both XHTML and HTML 5.
Validating Web Pages
The World Wide Web Consortium provides a Web page validation service to check for page conformance with standards. Although checking your pages for conformance is not necessary for pages to display properly in a browser, it is a good idea to submit pages to verify that they are indeed coded to standards.
The W3C validation service is available through the URL: http://validator.w3.org. This address displays the page shown in Figure 1-12.
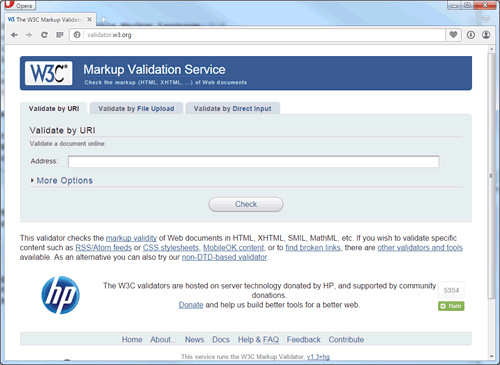
Figure 1-12.
W3C Validator page.
There are three options for validating pages. You can enter the URL for the page (making sure that the page is Web accessible), you can upload a Web document from your local PC, or you can paste your code into a text box. This latter technique is shown in Figure 1-13 where code for an example page is entered for validation.
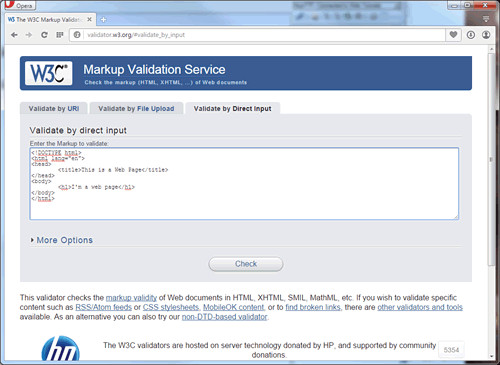
Figure 1-13.
Entering a web page for validation.
Since the !DOCTYPE entry on this page indicates conformance with HTML 5 standards, the page is validated against these standards. When the "Check" button is clicked, validation is performed and a report page is displayed.
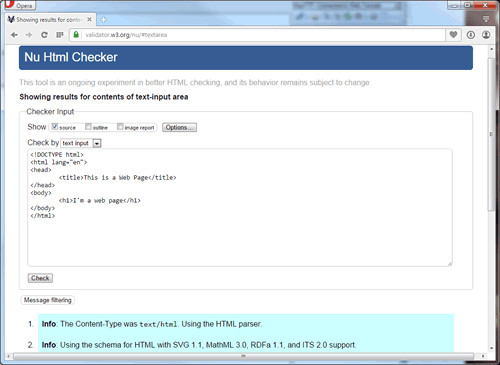
Figure 1-14.
Validator Report.
In this case, the HTML code is in conformance with standards (no red errors appear). If the document does not comport with standards, then errors are listed indicating those elements of the page that are incorrect. Remember, though, Web browsers tend to be forgiving of noncompliant code. The page is likely to display correctly even though it does not exactly meet standards.
HTML Tags Types
HTML formatting codes, or tags, surround the material to be formatted and are enclosed inside angled brackets ("<" and ">") to identify them as markup instructions. On the basis of these markup tags, the browser displays the page in the specified layout and style. Each Web page is described by its own separate HTML document containing whatever tags are necessary to structure and style the page according to the design envisioned by the page author.
Various types of HTML tags are used for different layout and styling purposes. The list below is one way to categorize tags according to their primary usages.
- Document Layout Tags. These tags are used to structure the HTML document. They organize the information content on a page so that text and graphical elements appear where you want them to appear. These are the tags you use to design the overall physical and visual relationships between page elements.
- Text Formatting Tags. These tags are used to apply font faces, styles, sizes, and colors to the text appearing on the page. They package and decorate the text content of the page.
- List Formatting Tags. Certain tags are used to organize text information into lists. List structures include bulleted lists, numbered lists, and others.
- Graphic Formatting Tags. These tags are used to position, size, and style drawings and pictures that appear on the page.
- Linking Tags. Web pages are hypertext documents. This means that there are linkages between them. With the click of a mouse, you can immediately jump from one page to another, or from one page to a particular location on another page. It is not necessary to traverse the pages sequentially. Therefore, certain tags are used to set up these linkages between pages and between different sections of a single page.
- Table Tags. Web pages provide information to visitors by displaying data. Often times data needs to be organized in tabular form, into rows and columns, for better presentation, readability, and understanding. Table tags permit you to arrange data into tables; they also can be used as structuring devices for laying out the entire content of Web pages.
- Form Tags. Forms are data collection devices. They are used to collect information from visitors in order to capture data for processing or to solicit visitor preferences about content displays. Forms are the mechanisms through which visitors interact with your Web page. A number of different form tags permit various means of user interaction.
- Multimedia Tags. Modern Web pages provide a multimedia experience by presenting audio and video information and entertainment along with text and graphic images. Certain tags are used to link to and play audio and video files through special media players that can be embedded on the Web page.
This tutorial is organized around these tag types. Initially, you will learn the various ways to arrange and style text for Web page presentation; then you will learn how to display graphic images, and how to use text and pictures as links to other Web pages. Thereafter, you will learn special content formatting through use of tables, frames, and forms, followed by integration of multimedia content on the page. In the end, you will learn most of the HTML tags needed to arrange and style page content to your exacting requirements.
Container and Empty Tags
HTML tags are special keywords surrounded by "<" and ">" angle brackets. These element "names" indicate the purpose of the tag and direct the browser to treat the enclosed content in a specified fashion. In the example page shown in Listing 1-6, the <html> tag surrounds all the content on the page and indicates that this is an HTML document that the browser should treat as such. That is, the browser should look for HTML tags and use the enclosed markup specifications to style the information surrounded by the tags. Likewise, <body> tags enclose all page content that is displayed inside the browser window. In conformance with HTML standards, all keywords are typed in lower-case characters.
Most HTML tags are coded as pairs of opening and closing tags called container tags. The opening tag is the keyword itself appearing inside < and > symbols; the closing tag is in the same format with the keyword preceded by a forward slash (/). This pair of container tags encloses the information to which the formatting applies. Thus, the pair of container tags <html>...</html> encloses the entire HTML document to indicate that everything in between is coded in HTML. In the same way, the pair of <body>...</body> container tags encloses all page content that is displayed inside the browser window.
Certain other tags are not container tags; that is, they do not "surround" information to be formatted, but are coded as single, stand-alone tags. EX: <br />, <img />, and <hr />
As the various tags are introduced in this tutorial you will quickly learn how to code container tags and empty tags, and will become familiar with the variations they permit.
Block-level and In-line Tags
Tags can also be classified as block-level or inline-level elements. Block-level elements create a line break and begin displaying content on a new line in the browser. After its content is displayed, another line break takes place to create a block of text set off from surrounding content in the browser. All groupings of content on a Web page must appear inside block-level tags.
A block-level tag differs from an in-line tag that produces no line breaks. Its enclosed content is embedded in-line within the stream of page elements, and is normally separated from surrounding content by a single blank space. Most XHTML tags are in-line tags.
It is important to remember the difference between block-level and in-line tags. Under HTML standards, all content must be coded inside block-level tags to identify these separate blocks of content that compose the page. Also, all in-line tags must appear inside block-level tags; that is, in-line content must be placed inside a block of text rather than appear stand-alone outside a block of text. Throughout these tutorials various tags are identified as block-level or in-line tags, and reminders are given regarding the need to always enclose in-line page elements inside block-level page elements.
Core HTML Attributes
HTML tags can have attributes that apply certain settings or characteristics to the tag. Under HTML, most attributes have been deprecated in favor of CSS; however, there are a special set of core attributes that are standard for all tags (with a few exceptions). Usage of these attributes will be discussed in more detail in upcoming tutorials.
| Attribute | Value | Description> |
|---|---|---|
| class | class or style rule | The class of the element (used with CSS) |
| id | id name | A unique id for the element |
| style | style definition | An inline style definition (used with CSS) |
| title | tool tip test | A text to display in a tool tip |
| dir | ltr (default) or rtl | Sets the text direction (left-to-right or right-to-left) |
Some of the new features of HTML 5 include:
- A canvas element for drawing
- Improved video and audio elements for media playback
- Content specific elements such as article, footer, header, nav, and section
- New form control elements, like calendar, date, time, email, url, and search
The HTML 5 DTD has been simplified as shown below:
<!DOCTYPE html>
A sample HTML 5 compliant page is coded below:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>Page Title Goes Here</title>
</head>
</body>
*
page content goes here
*
</body>
</html>
Cascading Style Sheets
HTML tags are identifiers and containers of text and graphic information appearing on a Web page. Their primary use is to describe the structure of that content to package it for placement on the page. However, most Web pages are more than straight text and in-line images placed there by HTML tags. The information on the page has styling applied to make it more attractive and readable. Various type faces, text sizes, colors, and other formatting characteristics make the page more inviting to read, and when used judiciously, can make the information more understandable.
Under previous versions of HTML, most of the styling of page content took place through attributes coded as part of its tags. Attributes provided additional formatting specifications beyond those implied by the tag name itself. For example, font styles could be assigned to text information by surrounding it with a <font> tag containing attributes to set the font face, size, and color: <font face='arial', size='4', color='red'>. Various tags supplied various attributes to format their contained content in various ways.
Under current versions of HTML, tag attributes have all but disappeared, being deprecated (depreciated in use) in favor of Cascading Style Sheets (CSS), or just "style sheets" for short. A style sheet is a set of styling characteristics associated with HTML tags. These styling characteristics are composed of style properties and values, written in the special syntax of style sheets, and assigned to the tags that will inherit these styles. For instance, one way to assign a style sheet to a tag is to include it as a style attribute inside the tag.
<p style='font-family:arial; font-size:14pt; color:red; font-weight:bold'> This is a text paragraph. </p>Listing 1-8. Assigning an inline style to a paragraph.
In the above example, a paragraph of text, surrounded by a <p> (paragraph) tag is given an Arial type face of size 14pt (14 points), colored red, and displayed in bold characters. Four property :value; specifications (e.g., font-family:arial) apply these styles. This is an example of including a style sheet as part of the tag to which it applies.
All HTML tags can be assigned one or more styling characteristics. there are hundreds of different style properties and values that can be applied. A large part of learning HTML is in learning these many styling possibilities. Styling categories include:
- Font Styles - for setting font faces, sizes, and weights.
- Text Styles - for setting letter and word spacing, line heights, horizontal and vertical spacing, and indentions.
- Color Styles - to set background and foreground colors.
- Border Styles - to display various borders surrounding text and graphic elements.
- Margin Styles - to assign various margin widths surrounding text and graphic elements.
- Filter Styles - to apply special effects to text and graphic elements.
- Sizing Styles - to set widths and heights for text and graphic containers.
- Positioning Styles - to position page elements at exacting pixel locations on the page.
The World Wide Web Consortium maintains standards for the Cascading Style Sheets language just as it does for the HTML markup language. The current version of standards followed in this tutorial is CSS Level 2.1 (CSS2).
The main task in learning HTML is learning the tags and their styling characteristics which apply browser formatting to whatever page content they enclose. The general practice in this tutorial is to present only those tags and style sheet settings that are essential to the discussion at hand. Additional tags and styling possibilities are introduced as you proceed through the tutorial.
It is worth noting that the examples shown in this tutorial are fairly simple illustrations of tags and styles. The intent is to emphasize the HTML code and basic styling approaches rather than to produce elaborate page displays. In this way you can focus on the code without being distracted by a great amount of informational content. Understand, however, that you can produce quite elaborate page displays by combining the basic set of HTML and style sheet elements presented here.
Validating CSS
The W3C maintains a free Markup Validation Service available at http://jigsaw.w3.org/css-validator that can be used to validate CSS code and check for syntax errors. The CSS validation tool can help identify code that needs to be corrected quickly and indicate which styling rules a browser is likely to consider valid.
1.4 - Working With Documents
Working with HTML Documents
HTML documents have a simple, common structure that forms the basis for designing all Web pages. This basic structure of tags is shown in the following listing with associated tags described in the following sections.
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8" /> <title>page title goes here</title> </head> </body> * page content goes here * </body> </html>Listing 1-9. A web page template.
As you begin coding an HTML page you can start with this template. In fact, you may wish to create this document and save it as a template file. Then, when you start a new page, simply open this document, save it under the name of the new page, and continue coding for the particular information to appear on that page.
The DTD
All HTML documents should begin with the prolog line shown in Listing 1-10. This first line is the Document Type Definition indicating the W3C coding standard used for the page. In this case, the standard used was HTML version 5.
<!DOCTYPE html>
Listing 1-10. Web Page DTD.
The<html> Tag
The <html> container tag surrounds all HTML coding in the document. This tag indicates that the enclosed information contains HTML coding and should be rendered as such in the browser. In conformance with HTML standards, the opening tag includes the lang attribute that specifies the specific language used for the content: English (en).
<html lang="en">Listing 1-11. The <html> tag.
The <head> Tag
The <head> container tag encloses the head section of the HTML document. The head section supplies a title for the document (see below) along with other information related to the formatting and indexing of the document. For present purposes, only a title appears in the head section. Other tags that can be included in the head section are discussed as needed.
<head> <title>page title goes here</title> </head>Listing 1-12. The <head> tag.
The <title> Tag
The <title> container tag gives a title to the document. This tag encloses a string of text that appears in the browser's Title Bar when the page is opened. The <title> tag provides helpful page identification information to the person visiting the various pages of your Web site. Note that <head> and <title> sections are required for conformance with HTML 5 standards.
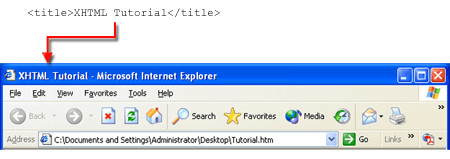
Figure 1-15.
Appearance of the <title> tag on the browser Title Bar.
The <body> Tag
The bulk of the coding of an HTML document appears in the body section surrounded by the <body> container tag. Only information appearing inside this tag is displayed in the browser window. In its simplest form, the body section contains plain text that is displayed in the default font style inside the browser window. Browsers normally display text using Times New Roman font face at approximately 1-em size.
All Web pages begin with this basic document structure. The <body> of the document is then expanded with text and other page elements that are to be displayed inside the browser window. Various arrangements of these display elements as well as control over their appearance are accomplished by enclosing them within additional HTML tags.
In order to view your work, it is not necessary to be connected to the Internet or to be linked to a server on the World Wide Web. You can do all your work locally. If you happen to have an account with an Internet Service Provider that provides personal home directories, then you can copy documents to your directory for viewing on the Web. For purposes of this tutorial, you can create Web pages on your computer's hard drive, on a removable thumb drive or diskette, and view the pages through your browser.
The Web pages created in these tutorials work correctly under Internet Explorer and other browsers that follow W3C standards. You should download the latest version of the browser you are using.
Text Editing with Notepad++
HTML documents are created with text editors or with special HTML editors designed for that purpose. For these tutorials, it is sufficient to use a simple text editor such as Windows Notepad++. After opening this application you enter the text and other page elements that you wish to display, and surround them with HTML tags for layout and styling.
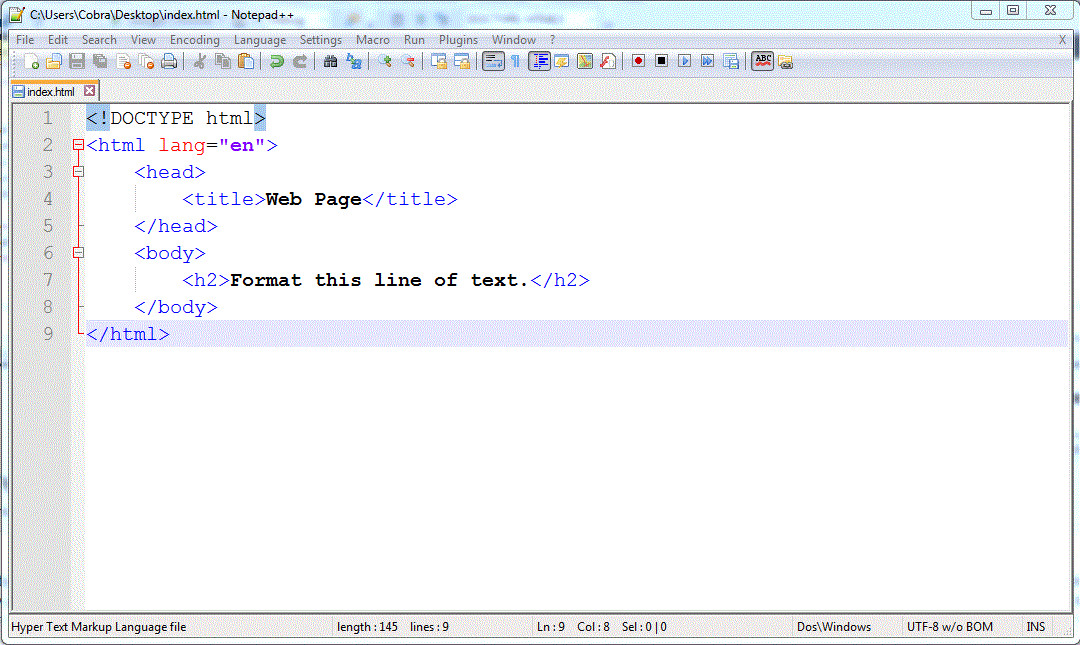
Figure 1-16.
The Notepad++ application with coding for a simple web page.
Text and coding is typed into the editor in free-format style. That is, blank spaces, tabs, indents, and other document editing techniques can and should be used to make the document readable in the editor. These editing layouts are ignored by the browser, which only pays attention to the HTML tags for page layout and formatting instructions. The above code, for example, would be displayed properly in the browser if it were entered in the editor as follows:
<!DOCTYPE html><html lang="en"><head><title>Web Page</title></head><body><h2>Format this line of text.</h2></body></html>Listing 1.16. Consecutive spaces, line returns, and tabs are ignored.
However, it is easier to compose and edit the document and to understand the layout of the page by spacing its tags and text in a more readable format. Take great care in alignment and indention of code so that it visually represents the structure of content that displays in the browser. Sloppy code inevitably leads to errors. You should choose a monospace font such as Courier New for displaying your code in Notepad++. The monospace font will better able you to align lines of text in the editor.
HTML coding is an exacting art and science. Accuracy of coding is paramount and you need to work with close to 100% accuracy. The browser doesn't know what you "wish" to do; it can only do what you explicitly tell it. At first, coding will be tedious and time consuming. As you practice and gain experience, you should be able to type and edit HTML code with not much more difficulty than straight text.
Saving an HTML Document
Once you have completed coding the HTML document, you need to save it so that it can be retrieved and displayed inside a browser. The document can be saved to your desktop, to a removable storage drive, or in a folder on your hard drive.
You can choose any file name you wish for your Web document, although you should not include any blank spaces or special characters in the name. You also need to make sure that you save the document with the .html or .htm file extension. This extension identifies the document as a Web page and it is needed for the browser to recognize it as such.
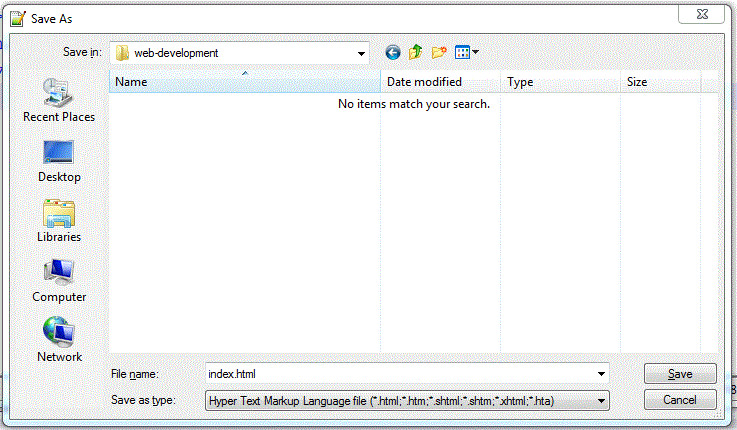
Figure 1-17.
Saving an HTML document under Notepad++
Displaying an HTML Document
The saved HTML document with the .html extension is now ready to be viewed in your browser. You can open the document directly in the browser by double-clicking its icon, or you can open your browser and use the File menu to navigate to the correct drive, folder, and document. When the document is loaded into the browser, the address appearing in the Address box of your browser indicates this path to the document.
Document Editing and Display
When composing a lengthy Web page, it is not necessary to code the entire page at one time. You can code a few lines, save the document, view the page in the browser, and then return to composing the next section of code. In other words, you can switch back and forth between the editor and the browser as you put together your Web page. Just start with the document template described earlier so that you are editing a complete, valid Web document.
To facilitate this sort of page development, leave both your editor and browser open on the desktop so that they are accessible in the Task Bar. Then you can making changes or corrections to your document and switch immediately to your browser to refresh and view the updated page.
The following illustration shows the computer screen with both Notepad and the browser opened at the same time on the desktop. It is now a simple matter of clicking in the Notepad window to edit the Web document. After saving the changes, click in the browser window and click the Refresh button to reload the changed document. Now switch back to Notepad to continue with page development.
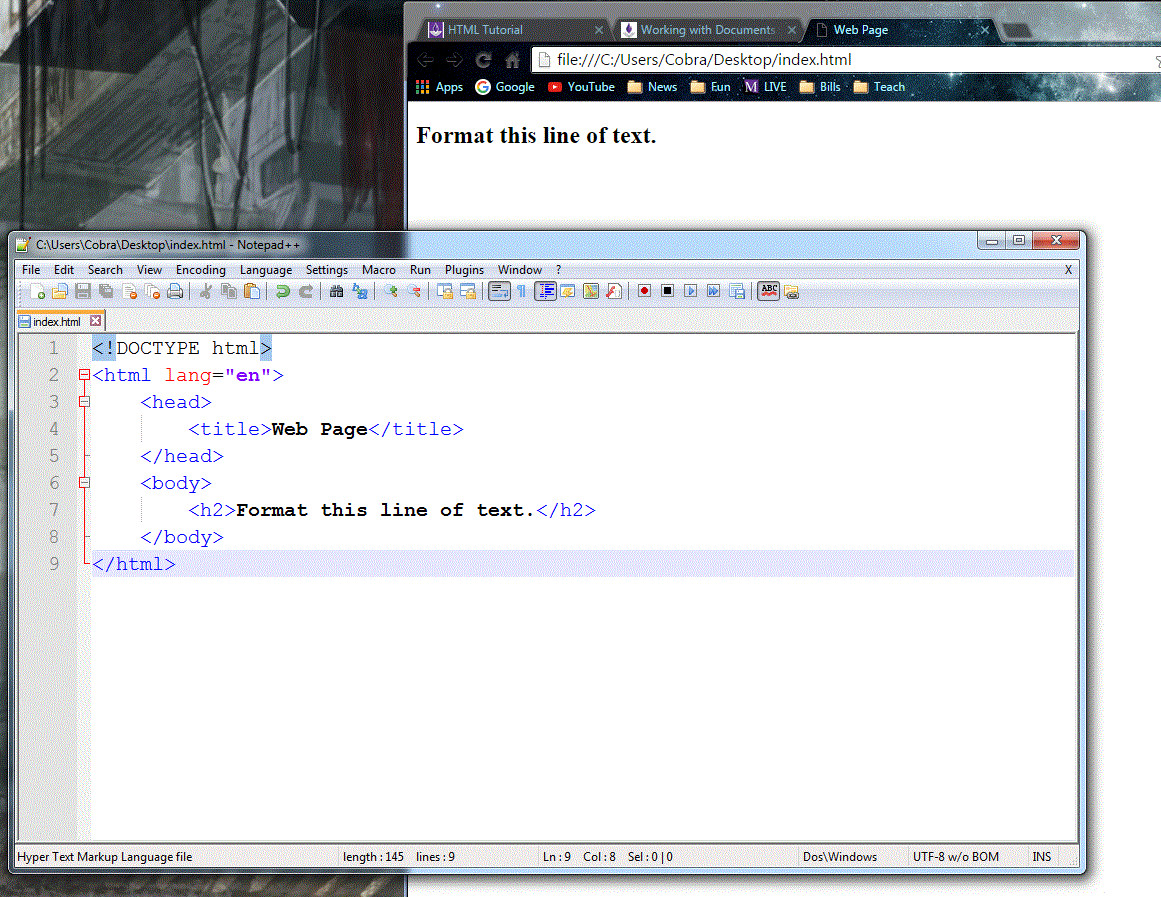
Figure 1-18.
Web page editor and browser open on the desktop.
1.5 - Creating Your First Web Page
Creating Your First Web Page
It is now time to create your first Web page and view it in your browser. This page is not very fancy but it will familiarize you with the process of coding, editing, saving, and retrieving a page for display in your browser. Begin by opening the Notepad++ editor and enter the text and code shown in the following listing.
<!DOCTYPE html> <html lang="en"> <head> <title>My First Web Page</title> </head> <body> <!-- Here is a paragraph for browser display --> <p>This is my first attempt at creating a Web page. I don't quite understand yet what I'm doing, but its seems easy enough. Perhaps when I learn a few more HTML tags and CSS styles I'll start feeling comfortable and will begin dazzling you with my skills.</p> </body> </html>Listing 1-13. Coding your first web page.
When entering the text paragraph, it is not necessary to type it line for line as in the example. If your editor permits word wrapping, you can take advantage of that; otherwise, and perhaps preferably, you can enter line breaks to maintain a consistent editing format. Remember, the browser ignores any spaces, tabs, and blank lines you enter in the editor, so type the information in the readable format you prefer.
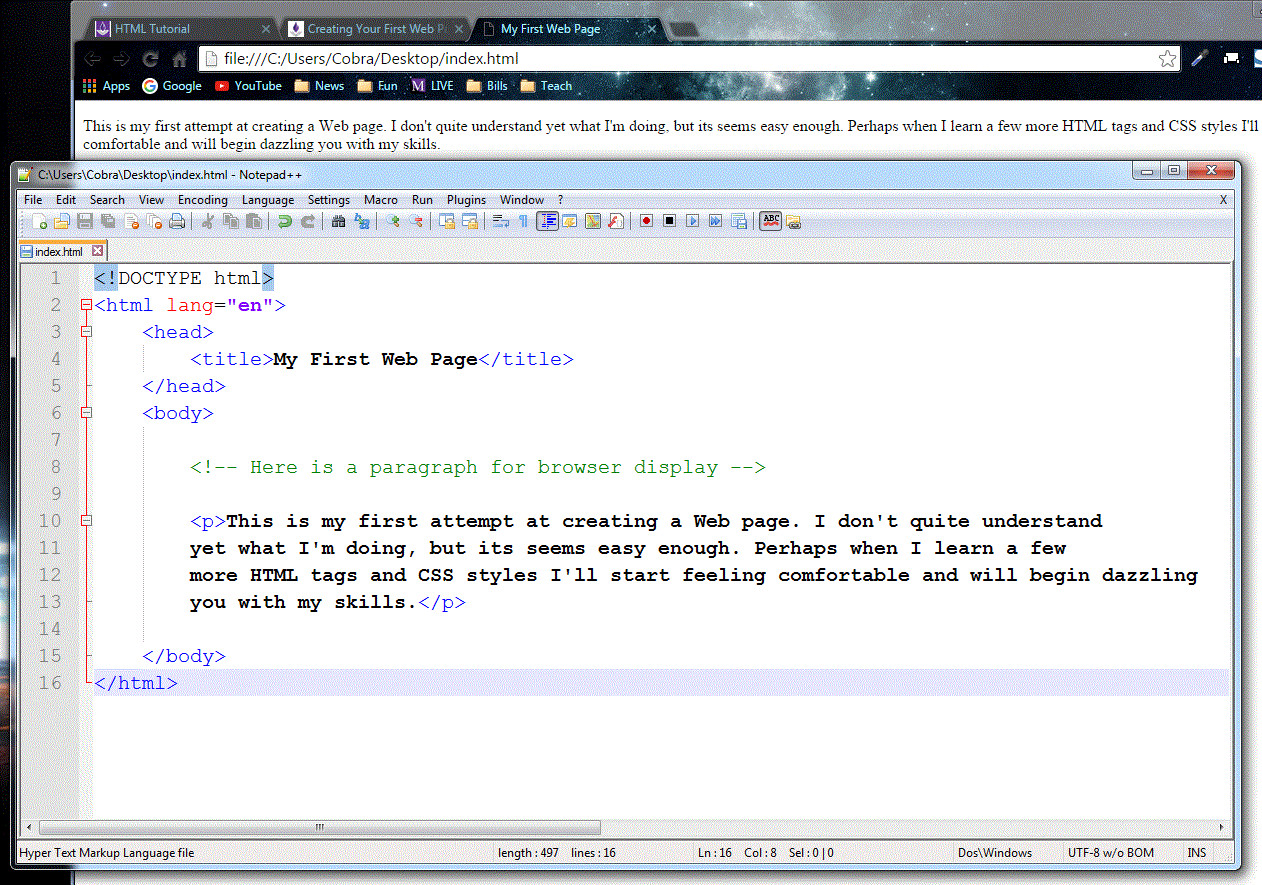
Figure 1.20.
Web page coding in Notepad++.
HTML Comments
It is usually a good idea to place comments in your Web document to describe its various sections. Comments are general descriptions or explanations of HTML code. These serve as useful reminders of the purposes or contents of sections of code when you or someone else returns at a later time to edit the document. In the above example, a general comment has been placed at the beginning of the <body> section.
<!-- Here is a paragraph for browser display -->
Comments are coded between a pair of <!-- & " and " & --> tags. These tags can enclose a single-line comment as illustrated above, or they can enclose multiple lines of HTML coding. Any code or text appearing between these symbols is ignored by the browser and does not show up on the page.
Besides their use for including comments in a document, comment tags can be used to temporarily suspend the browser display of a section of code. This purpose is often useful in "debugging" your page, that is, in trying to discover errors by selectively removing sections of code from display until the problem is isolated.
Saving and Displaying Your Web Page
After coding the page, save the document so that it can be retrieved by your browser. Where you save the document depends on your development environment. If you are working on a standard desktop PC, save the document to a diskette or to a folder on your hard drive. Remember to save the document with the special file extension .html. Save this current document under the name FirstPage.html or any other name of your choosing.
Now, open your browser and retrieve the page. You should leave your editor open on the desktop so that it is handy for making corrections or changes to your page. If you had coded your document as in the example above, your Web page should appear in the browser window similar in style to that shown below. This page has been retrieved from the local hard drive and displayed in the browser.
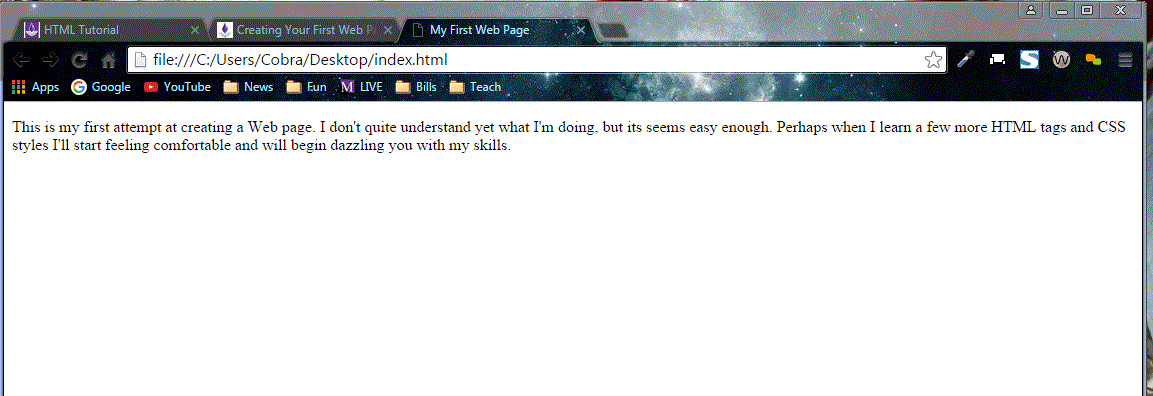
Figure 1-21.
Browser display of your first Web page.
Note that this browser display is not a full-size window, so your line lengths may appear slightly different. This difference illustrates the fact that the browser renders the document to fit within the dimensions of its display window. Any text on the page has its line lengths adjusted and word-wrapped to fit the window no matter how large or small the window has been sized.
Now that you have a basic feel for the process of coding and viewing Web pages, you can begin learning the HTML tags to make your documents more presentable. In the next section of the tutorial, tags are presented that control the structure of Web pages and the ways in which blocks of text are displayed.