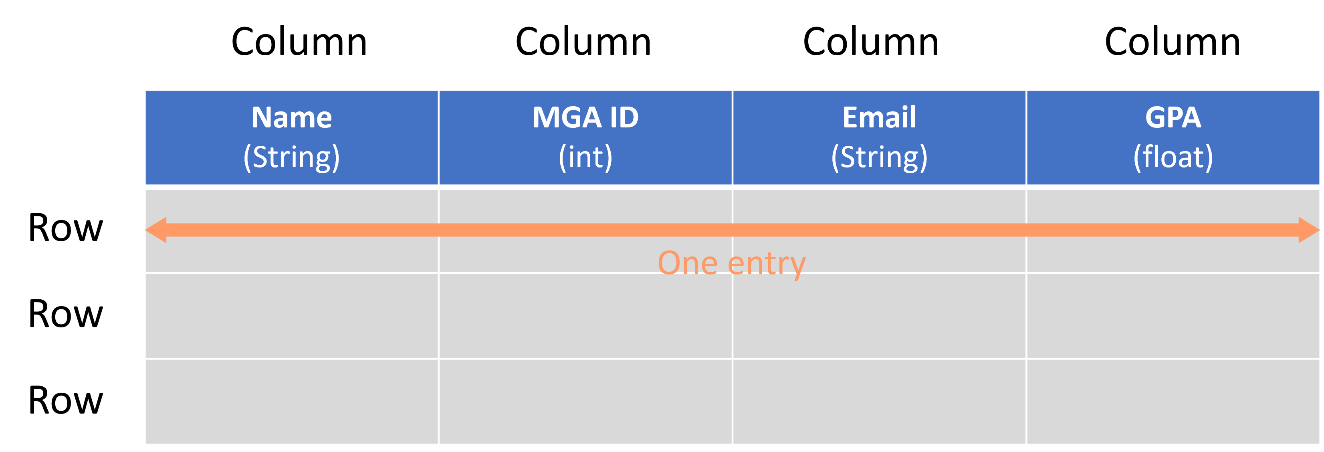
A Database Management System (DBMS) is responsible for storing data in a structured manner within a database. A database consists of one or more tables, each of which holds a collection of related data. These tables organize data into rows and columns. Each row represents a complete set of information about a single item, while columns contain individual pieces of data pertaining to the items in the table.
In SQLite, every data value has a specific storage category:
- NULL: Represents missing or unknown information
- INTEGER: Stores whole numbers, using a variable amount of space (0 to 8 bytes) based on the number's size
- REAL: Stores floating-point numbers (numbers with decimals) in a standardized 8-byte format
- TEXT: Holds text strings, encoded using the database's character set (typically UTF-8)
- BLOB (Binary Large Object): Stores raw binary data exactly as it was provided, without any interpretation
a) Primary key
A primary key is a column or set of columns that uniquely identifies each row in a table. The primary key constraint ensures that the values in this column (or columns) are unique and not null. It's used to uniquely identify each record in the table, making it easy to retrieve, update, or delete specific rows. For example, the MGA ID column serves as the primary key because each student has a unique ID number, allowing you to identify and work with individual student records efficiently.
b) Identify column
An identity column, also known as an auto-increment column, is a special type of column in a relational database table where unique integer values are automatically generated by the database management system (DBMS). These values are usually incremented by a set amount (e.g., by 1) each time a new row is inserted into the table.
Identity columns are commonly used to create primary keys when the table doesn't have a suitable candidate column to serve as a primary key. In such cases, the identity column can be designated as the primary key, ensuring each row in the table has a unique identifier.
This feature is particularly useful when dealing with tables that lack a natural key (a column or combination of columns that uniquely identifies each row), or when simplicity and consistency in key generation are desired.
c) Null values
In relational databases, a null value represents a missing or unknown value in a column. While it's acceptable for some columns to contain null values, primary key columns cannot have null values. This is because the primary key uniquely identifies each row in the table, and having a null value would mean that there could be multiple rows with the same undefined identifier, violating the uniqueness constraint of the primary key.