A hash code is generated by a hash function.HASH
The hash function in the simulation above takes the numbers in the social security number (not the dash), add them together, and does a modulo 10 operation (% 10) on the sum of characters to get the hash code as a number from 0 to 9.
This means that a person is stored in one of ten possible buckets in the Hash Map, according to the hash code of that person's social security number. The same hash code is generated and used when we want to search for or remove a person from the Hash Map.
The Hash Code gives us instant access as long as there is just one person in the corresponding bucket.
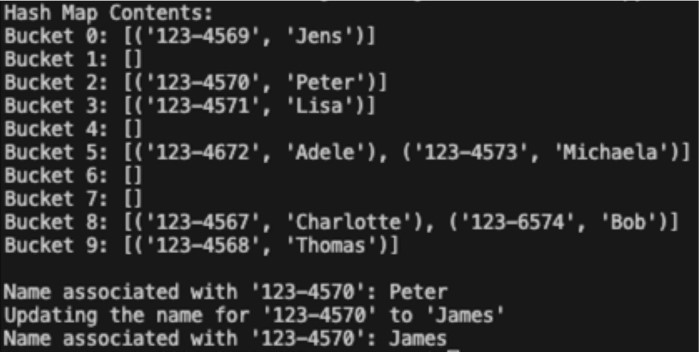
In the simulation above, Charlotte has social security number 123-4567. Adding the numbers together gives us a sum 28, and modulo 10 of that is 8. That is why she belongs to bucket 8.
Direct Access in Hash Maps
Searching for Charlotte in the Hash Map, we must use the social security number 123-4567 (the Hash Map key), which generates the hash code 8, as explained above.
This means we can go straight to bucket 8 to get her name (the Hash Map value), without searching through other entries in the Hash Map.
In cases like this we say that the Hash Map has constant time O(1) for searching, adding, and removing entries, which is really fast compared to using an array or a linked list.
But, in a worst case scenario, all the people are stored in the same bucket, and if the person we are trying to find is last person in this bucket, we need to compare with all the other social security numbers in that bucket before we find the person we are looking for.
In such a worst case scenario the Hash Map has time complexity O(n), which is the same time complexity as arrays and linked lists.
To keep Hash Maps fast, it is therefore important to have a hash function that will distribute the entries evenly between the buckets, and to have around as many buckets as Hash Map entries.
Having a lot more buckets than Hash Map entries is a waste of memory, and having a lot less buckets than Hash Map entries is a waste of time.
Hash Map Implementation
Hash Maps in Python are typically done by using Python's own dictionary data type, but to get a better understanding of how Hash Maps work we will not use that here.
To implement a Hash Map in Python we create a class SimpleHashMap.
Inside the SimpleHashMap class we have a method __init__ to initialize the Hash Map, a method hash_function for the hash function, and methods for the basic Hash Map operations: put, get, and remove.
We also create a method print_map to better see how the Hash Map looks like.
Output: